

Oh, Alpha Go, How Do You Know?
- Nov 24, 2021
- 11 min read
Updated: Nov 29, 2021
Last Saturday, I was sitting in a corner store Starbucks, talking to a friend about the artificial intelligence, AlphaGo, over the New York City bustle, an unexpected hailstorm, and the loud whizzing of coffee machines around us. Amidst the chaotic energy, his eyes beamed in awe and wonder about the "superhuman" computer program while I refrained from over-personifying it. The conversation soon took a detour into thoughts on Plato's Allegory of the Cave, (yes, it was that kinda nerdy) and I was left feeling unsatisfied with how limited our discussion about AlphaGo was, beyond his marvel over the advancement of machine learning and my hesitance to call it more than what it is: math, probabilities, and a brilliant algorithm.
A few days later, my friend's questions were still lingering in the back of my mind... "But how does AlphaGo know?", "How does it see so many moves ahead?", "How did it learn to think better than humans?" which led me to wonder if a huge part of his amazement with AlphaGo and similar technologies stems from the mystery of not knowing everything under the hood. Before I knew it, I found myself deep diving into the technology and looking for a way to answer his questions to possibly demystify exactly how AlphaGo works.
So, over the past week or so, I have been piecing together information from across the internet, my experience as a data scientist, and resources from my previous AI courses to write a comprehensive and foundational series of blog posts for understanding the novelty of AlphaGo, the actual machine learning behind it, and, in doing so, a window into how to think like an artificial intelligence engineer. While I did break down this series as best as I could to accommodate audiences with no artificial intelligence background let alone technical backgrounds, it is still a hefty set of documents that contains just about a semester's worth of AI squished into a nutshell. But if you want to be able to speak about technologies like AlphaGo on your next coffee date then this'll be worth the ride.
Part 1| Introduction to Go as an Artificial Intelligence Problem
If you haven't already read my post, Intro to AI Bias, it covers the absolute fundamentals for understanding and defining artificial intelligence as a concept, philosophy, and integral part of our world. This may be a helpful read. Today, we'll be going into the following three topics to create a foundation for understanding the method behind AlphaGo.
Overview of AlphaGo and Go
Developed by DeepMind Technologies, a subsidiary of Google, AlphaGo is an example of game-playing artificial intelligence. It "is the first computer program to defeat a professional human Go player, the first to defeat a Go world champion, and is arguably the strongest Go player in history." Many earlier computer programs had limited ability to maneuver the complexities of the game, Go, playing only at amateur levels. In March 2016, AlphaGo beat 18-time world champion Lee Sedol in a historical five-game Go match after which it was praised not simply for its victory but also for its unorthodox moves. A year later, in 2017, AlphaGo beat another world champion, Ke Jie, showing even more improved performance than in the previous year. (1)
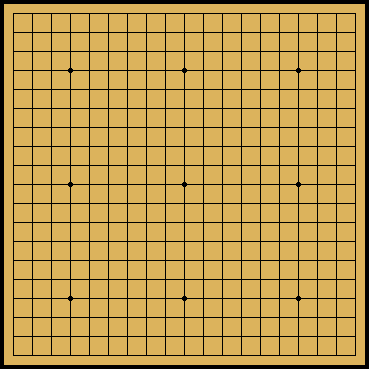
The origins of Go date back some 4,000 years ago to ancient China and is said to be the world's oldest game to still be played today. (2) The rules of Go are very simple. The game begins as a 19 x 19 blank grid, the board, with 181 black stones and 180 white stones for two opposing players to use. In total, these 361 stones correspond with the number of intersections on the aforementioned standard Go board. Beginning with the player that holds the black stones, each player takes turns strategically placing a stone at one of the intersections on the board. The two players are called Black and White, respectively. The objective of the game is to control more territory through the placement of these stones than the opponent by the end of the game. The rules of Go are very simple, but the strategy that goes into the game is complex and has been studied over centuries. (3)
You can imagine the surprise across the Go community when a computer program beat centuries of strategizing with a few untraditional moves. Experts of the community are now turning to AlphaGo as a teacher for innovating new ways to think about the game! In order to understand how the artificial intelligence community went from struggling to create a decent Go player to creating the master of Go, we need to first understand some of the fundamentals of how to interpret Go as an artificial intelligence problem.
Artificial Intelligence Problem Spaces
A machine learning engineer will often begin to look at a problem by understanding its problem space. A problem space "refers to the entire range of components that exist in the process of finding a solution to a problem" (4). In artificial intelligence, a problem space usually contains states, actions, and agents.

A single state represents all of the elements of a problem at a given moment, or a specific "state" of the problem. Most states have one or more actions that can be taken to transition the problem to a new state. The initial state is the original state of the problem space before any actions are taken. A terminal state is a state from which there are no possible actions to be taken to get to another state. A terminal state is a goal state if there are no possible actions to be taken because the objective, or goal, of the problem state has been met. An agent (or agents) is the entity within the problem space that chooses an action to move from state to state, beginning with the initial state, until a terminal state is reached.

In a simple game of Tic-Tac-Toe, there are two agents: player one (O) and player two (X). The initial state, S0, is an empty board with it being O's turn to make a move. From S0, the first agent chooses to take the action of placing O in the center of the board, A1, which changes the state of the problem to S1, where an O is in the center of the board with it being X's turn to make the next move. The agents take turns choosing actions that move the problem from state to state until a terminal state is reached. Here, the terminal state is not the goal state because the objective to win the Tic-Tac-Toe game has not been met. You can imagine how this can be adapted to other games such as Chess or Go.
From the initial state, S0, above, there are nine possible actions to take: placing an O on the top left corner, top middle space, top right corner, second left space, center of the board, second right space, bottom left space, bottom middle space, and the bottom right space. Each of these actions leads to a different state. And from there, every state has another set of actions that lead to another set of states. All of the possible combinations of states and actions is called a state space. The state space for the Tic-Tac-Toe game is 3⁹ (19683 possible ways the game can be played out) because there are 9 spaces and each of these spaces can be one of 3 things: empty, O, or X.
To understand the problem space, engineers will contextualize the problem within its environmental conditions, or the conditions that surround the problem. These four conditions are: the observability of each state, the determinability of the state space, the continuity of the state space, and the nature of any agents within it.
1) Observability:
A state of a problem is either fully observable or partially observable. A fully observable environment has states that are known and transparent at all points in the game. The Tic-Tac-Toe game is fully observable because the information available at a given state is the only information needed to understand which move to make next. There is no additional, hidden information that needs to be known before choosing an action.
On the contrary, a partially observable environment has states that do not contain all of the information needed at a given point in time. An example of this is in a game of poker. In any state of a poker game, an agent would benefit from knowing which cards have already been drawn during other states of the game. The advantage that an agent gains from this knowledge would provide it superior decision-making for the best next move to make as opposed to not knowing this information. Hence, the concept of counting cards. But because this information is not available at a given state of the game, and requires historical information, poker is considered to have a partially observable environment.
2) Determinability:
A state space is either deterministic or stochastic. A deterministic state space is one that has a definitive set of states, derived from each action. Every action leads to an expected state, from the previous, without any hidden surprises or element of unpredictability. For example, when O chooses the action to place O in the center of the board, the next state is always going to be a board with an O in the center.
A stochastic state space is the opposite: it's one that cannot be determined definitively by the current state and actions. A common example used to exemplify a stochastic space is a self-driving car. The environment of a car, in real life, is very unpredictable and random. Regardless of the agent's decisions, there are uncontrollable environmental circumstances that may lead an action to an unexpected result.
3) Continuity:
A state space is also either continuous or discrete. In a continuous state space, there is an infinite amount of possible actions and states. The self-driving car is a great example to understand a continuous state space. There are so many combinations of moves for a self-driving care to make, from the angle of a turn to the speed of the vehicle and even more variables. Therefore, the state space of a self-driving car is not only stochastic, but also continuous.
Unlike a continuous state space, a discrete one has a countable set of possibilities. Most board games have a continuous state space, regardless of how large the state space is. Examples include Tic-Tac-Toe, Chess, Checkers, and Go.
4) Nature of Agent:
Most times, an AI problem is defined from the perspective of one agent: the agent that is making decisions about how to drive a car, the agent that is playing Go against another person, the agent that is deciding how to move a Rumba around the room to clean it, etc. We'll call this agent the protagonist.
A state space will either be a single-agent or multi-agent environment. A single-agent environment would contain one agent that is interacting with the problem space. An example of this would be a Rumba which interacts with the environment, alone, and cleans the world around it.
A multi-agent environment is one in which there are more than one agents involved. For example, an online soccer game will include multiple agents in it. A multi-agent environment can further be defined as benign, collaborative, or adversarial. A benign environment will include multiple agents whose actions do not affect one another's goals. An example would be a problem space in which there is a vacuuming agent and a painting agent in the same room. They both have jobs and are working in the same environment but not actually hurting each other.
A collaborative environment will have multiple agents that are working together to meet a goal. Going back to the self-driving cars, if we lived in a world in which there are only self-driving cars, they would be able to communicate with one another to achieve the same goal of getting their passengers to a destination in one piece.
An adversarial environment will have multiple agents that are working against one another to meet their individual goals. For example, a board game with two players will be considered adversarial. In Tic-Tac-Toe, O wants to win and X wants to win. If O wins X cannot win and if X wins O cannot win. So, they are both adversaries to one another.
How do these environmental conditions look in the context of Go?
Go has a multi-agent, adversarial, deterministic, fully observable, and stochastic environment.
fully observable: At any point in the game, a state contains all of the information needed for an agent to make a move.
stochastic: An action from one state will lead directly to another, identifiable state without any random force affecting it into a different, unexpected state.
discrete: There are approximately 2.1 x 10¹⁷⁴ possible moves that can be made in the game of Go. Though this is a considerably large amount of moves, hence a large state space, it is still a countable one.
adversarial, multi-agent: There are two players involved, who are against one another which makes it an adversarial, multi-agent environment.
The simplest combination of environmental conditions is: fully observable, stochastic, discrete, single-agent, and benign. But most board games, including Go, are multi-agent and adversarial, which adds a level of complexity that the protagonist agent needs to account for. It's probably the reason why board games have been such a fun and enlightening way to gage the capabilities of artificial intelligence. Knowing how to identify a problem space is the first thing to figuring out which approach to take for solving the problem.
Two basic concepts for AI problem solving are 1) constraint propagation and 2) search. Constraint propagation is a method by which an agent will gather information about the restrictions of a problem in order to dramatically narrow down the state space. Search is a method by which an agent looks for the best solution when the agent comes across multiple choices to make at any point in the problem space. Search is primarily used in AI for game-playing and route planning, which is why our focus for this series will be on search problems.
Game Trees
The foundation of a basic search problem is a search tree. In general, a search tree is one of the many data structures, or ways to hold data, that computer scientists use. It has a similar structure to a tree, giving it the name. When this tree holds information about a game it is also commonly referred to as a game tree, and we use a tree for game-playing problem solving because it is one of the best ways to conceptualize all of the possibilities in the state space of a search problem.

Since we already have an understanding of states and actions in a problem space, it should be easy to translate this knowledge into the structure of a search tree. A state is represented as a node and an action is represented as an edge. Beginning with a tree's root node, which is equivalent to the initial state, it branches out (for each action) into child nodes, or all of the subsequent states. Each of these nodes, or states, branches out (for each action) into its own child nodes, becoming parent nodes. This branching of edges from parent node to child node continues until all of the leaf nodes, or terminal states, are reached.
Below is what the top of a tree would look like for a simple game of Tic-Tac-Toe.

Notice, though, that Figure 2.2 is only partially expanded. In order to show the entire game tree, we'd need a lot more space, but it isn't quite worth it to draw out.
I use Tic-Tac-Toe as an easy example, but this game tree is the same type of data structure that is used by engineers to map out the possible moves in a game of Go. Every state of the game has a node, and each node has all of the possible moves and actions that can be made from it. In the game of Go, the root node would be the blank 19 x 19 grid. The child nodes would be every configuration of black stones as the first move. The child nodes of each of those child nodes would be every configuration of white stones, following that node's black stone placement. So on and so forth. Like the Tic-Tac-Toe game tree, each node is a state in the game, and each edge is an action from these nodes.
These game trees are the fundamental data structures for holding all of the basic information needed for an agent to make decisions throughout a search problem. Next week, we'll look into how the search tree is used in a search problem, the short comings of these methods, and how they can be improved upon to get us one step closer to the "brain" behind AlphaGo.
Til next time,
Michelle
Sources:

Comments